Introduction
In a diplomatic context the word protocol refers to a diplomatic document or a rule,guideline etc which guides diplomatic behaviour. Synonyms are procedure and policy. While there is no generally accepted formal definition of "protocol" in computer science, an informal definition, based on the previous, could be "a description of a set of procedures to be followed when communicating". In computer science the word algorithm is a synonym for the word procedure, so a protocol is to communications what an algorithm is to computations.
Communicating systems use well-defined formats for exchanging messages. Each message has an exact meaning intended to provoke a defined response of the receiver. A protocol therefore describes the syntax, semantics, and synchronization of communication. A programming language describes the same for computations, so there is a close analogy between protocols and programming languages: protocols are to communications what programming languages are to computations.

Figure 1. Using a layering scheme to structure a document tree.
An effective model to this end is the layering scheme or model. In a layering scheme the documents making up the tree are thought to belong to classes, called layers. The distance of a sub-document to its root-document is called its level. The level of a sub-document determines the class it belongs to. The sub-documents belonging to a class all provide similar functionality and, when form follows function, have similar form.
The communications protocols in use on the Internet are designed to function in very complex and diverse settings, so they tend to be very complex. Unreliable transmission links add to this by making even basic requirements of protocols harder to achieve.
To ease design, communications protocols are also structured using a layering scheme as a basis. Instead of using a single universal protocol to handle all transmission tasks, a set of cooperating protocols fitting the layering scheme is used.
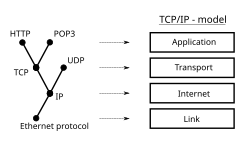
Figure 2. The TCP/IP model or Internet layering scheme and its relation to some common protocols.
The layering scheme in use on the Internet is called the TCP/IP model. The actual protocols are collectively called the Internet protocol suite. The group responsible for this design is called the Internet Engineering Task Force (IETF).
Obviously the number of layers of a layering scheme and the way the layers are defined can have a drastic impact on the protocols involved. This is where the analogies come into play for the TCP/IP model, because the designers of TCP/IP employed the same techniques used to conquer the complexity of programming language compilers (design by analogy) in the implementation of its protocols and its layering scheme.
Like diplomatic protocols, communications protocols have to be agreed upon by the parties involved. To reach agreement a protocol is developed into a technical standard. International standards are developed by the International Organization for Standardization (ISO).
Communicating systems
The information exchanged between devices on a network or other communications medium is governed by rules (conventions) that can be set out in a technical specification called a communication protocol standard. The nature of the communication, the actual data exchanged and any state-dependent behaviors are defined by the specification. This approach is often taken for protocols in use by telecommunications.
In digital computing systems, the rules can be expressed by algorithms and datastructures, raising the opportunity of hardware independency. Expressing the algorithms in a portable programming language, makes the protocol software operating system independent. The protocols in use by an operating system itself, lend themselves to be described this way and are usually, just like the rest of the operating system, distributed in binary or source form.
Operating systems are usually conceived of as consisting of a set of cooperating processes that manipulate a shared store (on the system itself) to communicate with each other. This communication is governed by well understood protocols and is only a small part of what a process is supposed to accomplish (managing system resources like cpu's, memory, timers, I/O devices etc, and providing controlled access to the resources), so these protocols can be embedded in the process code itself as small additional code fragments.
In contrast, communicating systems have to communicate with each other using shared transmission media, because there is no common memory. Unlike a memory store operation, a transmission doesnot need to be reliable and can involve different hardware and operating systems on different systems. This complicates matters up to a point that some kind of structuring is necessary to conquer the complexity of networking protocols, especially, when used on the Internet. The communicating systems can make use of different operating systems, as long as they agree to use the same kind of structuring and the same protocols for their communications.
To implement a networking protocol, the protocol software modules are to be interfaced with a framework assumed to be implemented on the machine's operating system. This framework implements the networking functionality of the operating system. Obviously, the framework needs to be as simple as it can be, to allow for an easier incorporation into the operating systems. The best known frameworks are the TCP/IP model and the OSI model.
At the time the Internet was formed, layering had proven to be a successful design approach for both compiler and operating system design and given the similarities between programming languages and communication protocols, it was intuitively felt that layering should be applied to the protocols as well. This gave rise to the concept of layered protocols which nowadays forms the basis of protocol design.
Systems do not use a single protocol to handle a transmission. Instead they use a set of cooperating protocols, sometimes called a protocol family or protocol suite. Some of the best known protocol suites include: IPX/SPX, X.25, AX.25, AppleTalk and TCP/IP. To cooperate the protocols have to communicate with each other, so there is an unnamed 'protocol' to do this. A technique used by this 'protocol' is called encapsulation, which makes it possible to pass messages from layer to layer in the framework.
The protocols can be arranged on functionality in groups, for instance there is a group of transport protocols. The functionalities are mapped on the layers, each layer solving a distinct class of problems relating to, for instance: application-, transport-, internet- and network interface-functions. To transmit a message, a protocol has to be selected from each layer, so some sort of multiplexing/demultiplexing takes place. The selection of the next protocol, also part of the aforementioned 'protocol' is accomplished by extending the message with a protocolselector for each layer.
There's a myriad of protocols, but they all only differ in the details. For this reason the TCP/IP protocol suite can be studied to get the overall protocol picture. The Internet Protocol (IP) and the Transmission Control Protocol (TCP) are the most important of these, and the term Internet Protocol Suite, or TCP/IP, refers to a collection of its most used protocols. Most of the communication protocols in use on the Internet are described in the Request for Comments (RFC) documents of the Internet Engineering Task Force (IETF). RFC1122, in particular, documents the suite itself.
Basic requirements of protocols
The data representing the messages is to be sent and received on communicating systems to establish communications. Protocols should therefore specify rules governing the transmission. In general, much of the following should be addressed:
Data formats for data exchange. In digital message bitstrings are exchanged. The bitstrings are divided in fields and each field carries information relevant to the protocol. Conceptually the bitstring is divided into two parts called the header area and the data area. The actual message is stored in the data area, so the header area contains the fields with more relevance to the protocol. The transmissions are limited in size, because the number of transmission errors is proportional to the size of the bitstrings being sent. Bitstrings longer than the maximum transfer unit (MTU) are divided in pieces of appropriate size. Each piece has almost the same header area contents, because only some fields are dependent on the contents of the data area (notably CRC fields, containing checksums that are calculated from the data area contents).
Address formats for data exchange. The addresses are used to identify both the sender and the intended receiver(s). The addresses are stored in the header area of the bitstrings, allowing the receivers to determine whether the bitstrings are intended for themselves and should be processed or (when not to be processed) should be discarded. A connection between a sender and a receiver can be identified using an address pair (sender address, receiver address). Usually some address values have special meanings. An all-1s address could be taken to mean all stations on the network, so sending to this address would result in a broadcast on the local network. Likewise, an all-'0's address could be taken to mean the sending station itself (as a synonym of the actual address). Stations have addresses unique to the local net, so usually the address is conceptually divided in two parts: a network address and the station address. The network address uniquely identifies the network on the internetwork (a network of networks). The rules describing the meanings of the address value are collectively called an addressing scheme.
Address mapping. Sometimes protocols need to map addresses of one scheme on addresses of another scheme. For instance to translate a logical IP address specified by the application to a hardware address. This is referred to as address mapping. The mapping is implied in hierarchical address schemes where only a part of the address is used for the map address. In other cases the mapping needs to be described using tables.
Routing. When systems are not directly connected, intermediary systems along the route to the intended receiver(s) need to forward messages (instead of discarding them) on behalf of the sender. Determining the route the message should take is called routing. On the Internet, the networks are connected using routers (gateways). This way of connecting networks is called internetworking. To determine the next router on the path to the destination, all systems consult locally stored tables consisting of (destination network address, delivery address) - entries and a special entry consisting of (a 'catch-all' address, default router address). The delivery address is either the address of a router assumed to be closer to the destination and the hardware interface to be used to reach it, or the address of a hardware interface on the system directly connecting a network. The default router is used when no other entry matches the intended destination network.
Detection of transmission errors is necessary, because no network is error-free. Bits of the bitstring become corrupted or lost. Usually, CRCs of the data area are added to the end of packets, making it possible for the receiver to notice many (nearly all) differences caused by errors, whilst recalculating the CRCs of the received packet and comparing them with the CRCs given by the sender. The receiver rejects the packets on CRC differences and arranges somehow for retransmission.
Acknowledgements of correct reception of packets by the receiver are usually used to prevent the sender from retransmitting the packets. Some protocols, notably datagram protocols like the Internet Protocol (IP), do not acknowledge.
Loss of information - timeouts and retries. Sometimes packets are lost on the network or suffer from long delays. To cope with this, a sender expects an acknowledgement of correct reception from the receiver within a certain amount of time. On timeouts, the packet is retransmitted. In case of a broken link the retransmission has no effect, so the number of retransmissions is limited. Exceeding the retry limit is considered an error.
Direction of information flow needs to be addressed if transmissions can only occur in one direction at a time (half-duplex links). To gain control of the link a sender must wait until the line becomes idle and then send a message indicating its wish to do so. The receiver responds by acknowledging and waits for the transmissions to come. The sender only begins transmitting after the acknowledgement. Arrangements have to be made to accommodate the case when two parties want to gain control at the same time.
Sequence control. We have seen that long bitstrings are divided in pieces, that are send on the network individually. The pieces may get 'lost' on the network or arrive out of sequence, because the pieces can take different routes to their destination. Sometimes pieces are needlessly retransmitted, due to network congestion, resulting in duplicate pieces. By sequencing the pieces at the sender, the receiver can determine what was lost or duplicated and ask for retransmissions. Also the order in which the pieces are to be processed can be determined.
Flow control is needed when the sender transmits faster than the receiver can process the transmissions or when the network becomes congested. Sometimes, arrangements can be made to slow down the sender, but in many cases this is outside the control of the protocol.
Getting the data across is only part of the problem. The data received has to be evaluated in the context of the progress of the conversation, so a protocol has to specify rules describing the context and explaining whether the (form of the) data fits this context or not. These kind of rules are said to express the syntax of the communications. Other rules determine whether the data is meaningful for the context in which the exchange takes place. These kind of rules are said to express the semantics of the communications.
Both intuitive descriptions as well as more formal specifications in the form of finite state machine models are used to describe the expected interactions of the protocol. Formal ways for describing the syntax of the communications are Abstract Syntax Notation One (a ISO standard) or Augmented Backus-Naur form (a IETF standard).



